推荐系统模型之Wide&Deep
Wide&Deep 简称WDL,是2016年Google 发表得一篇论文《Wide & Deep Learning for Recommender Systems》提出的推荐框架。
Wide&Deep 模型由单层的 Wide 部分和多层的 Deep部分组成。这样的组合使得模型兼具了逻辑回归和深度神经网络的优点,能够快速处理并记忆大量历史行为特征, 并且具有强大的表达能力, 不仅在当时迅速成为业界争相应用的主流模型, 而且衍生出了大量以Wide\&Deep 模型为基础结构的混合模型, 影响力一直延续到至今。
主要思路
Wide&Deep围绕着“记忆”(Memorization)与“泛化”(Generalization)两个词展开
记忆能力可以理解为模型直接学习并利用(exploiting)历史数据中物品或者特征的共现频率的能力
泛化能力可以理解为模型传递特征的相关性以及发掘(exploring)稀有特征和最终标签相关性的能力
Wide部分通过线性模型处理历史行为特征,有利于增强模型的记忆能力,但依赖人工进行特征组合的筛选
Deep部分通过embedding进行学习,对特征的自动组合,挖掘数据中的潜在模式有利于增强模型的泛化能力
模型结构
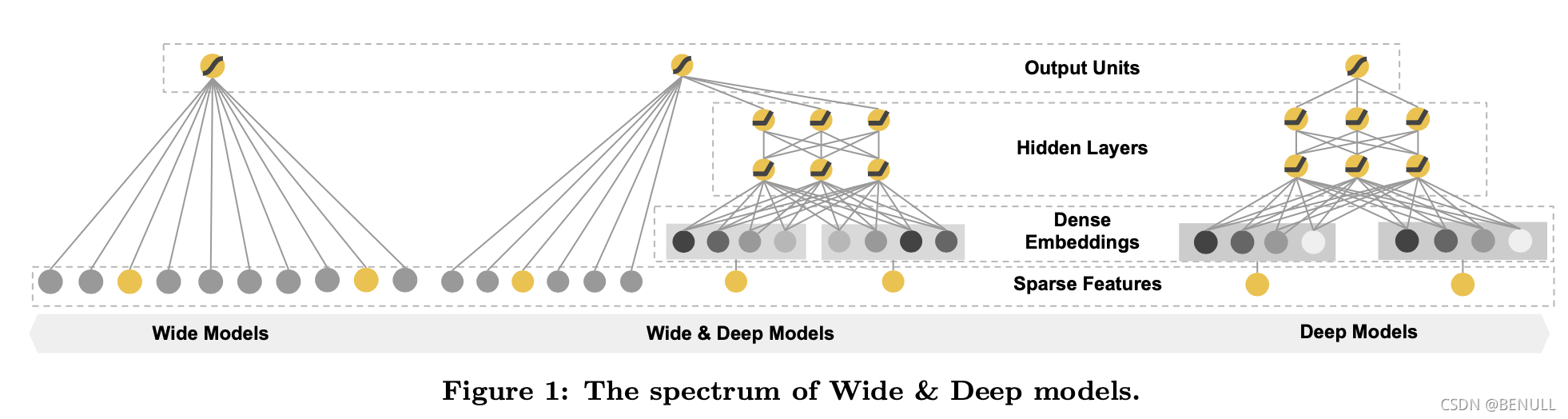
Wide部分
Wide部分善于处理稀疏类的特征,是个广义线性模型
$X$特征部分包括基础特征和交叉特征,其中交叉特征可起到添加非线性的作用。
交叉特征
文中提到过的特征变换为交叉乘积变换(cross-product transformation)
$C_{ki}$是一个布尔变量,当$i$个特征属于第$k$个特征组合时,值为1,否则为0。
例如对于特征组合”AND(gender=female, language=en)”,如果对应的特征“gender=female” 和“language=en”都符合,则对应的交叉积变换层结果才为1,否则为0
Deep部分
Deep模型是个前馈神经网络,对稀疏特征(如ID类特征)学习一个低维稠密向量,与原始特征拼接后作为MLP输入前向传播
Wide&Deep
Wide部分和Deep部分的输出进行加权求和作为最后的输出
其中文中提到Wide部分和Deep部分的优化器不相同,Wide部分采用基于L1正则的FTRL而Deep部分采用AdaGrad。
其中FTRL with L1非常注重模型的稀疏性,也就是说W&D是想让Wide部分变得更加稀疏
更多相关可参考见微知著,你真的搞懂Google的Wide&Deep模型了吗?
实现
TensorFlows调用
Wide&Deep模型可以直接通过Tensorflow进行调用
1 | tf.keras.experimental.WideDeepModel( |
Example:
1 | linear_model = LinearModel() |
自己实践
Model
1 | class WideDeep(Model): |
Modules
1 | class Linear(Layer): |