Spatial Residual Layer and Dense Connection Block Enhanced Spatial Temporal Graph Convolutional Network for Skeleton-Based Action Recognition
基于骨架动作识别的空间残差层和密集连接块增强的时空图卷积网络
来源
| 作者单位 | 会议 | 论文地址 | 代码 |
|---|---|---|---|
| 江南大学 | ICCV 2019 | 论文地址 | 暂无 |
创新点
引入了空间残差层来捕获和融合时空特征
在先前的工作中,时空层包括空间图卷积和时间卷积。但是不同卷积的序列叠加会混合不同域的信息,从而导致识别不准确。通过引入跨域空间残差卷积,可以增强时空信息
此外,提出了一个密集连接块来提取全局信息
它由多个空间残差层组成。在这些层中,可以通过密集连接来传递信息。
结合上面提到的两个组件来创建了一个时空图卷积网络(ST-GCN),称为SDGCN

图1.该方法将2D空间卷积与1D时间卷积集成在一起,用于时空特征表示,用于基于骨骼的动作识别。 蓝色方块代表空间图卷积,黄色代表时间卷积。
网络结构
主要工作:空间残差层和密集连接块增强的时空图卷积网络
空间残差层Spatial Residual Layer (SRL)
ResNet 首先通过引入残差结构来提出残差连接的概念,其中输入节点信息通过恒等映射传递。残差映射的想法是删除相同的主要部分,从而突出显示较小的更改。通过引入残差映射,整个结构对输出的变化更加敏感。残差层可以看作是一个放大器,经过合理的设置,敏感信息会被放大,因此残差连接只需要关心它需要学习的内容即可。
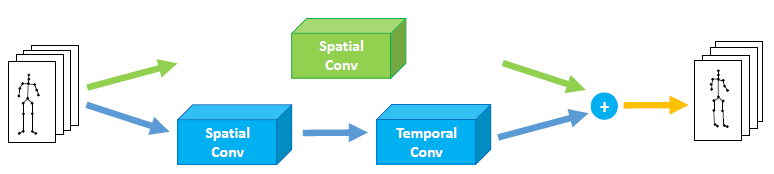
图2.空间残差ST-GCN层。 下部是ST-GCN层,由空间图卷积和时间卷积组成,上部是空间图卷积。 就像在ResNet中一样,残差连接的输入与ST-GCN层相同,然后将从残差连接获得的输出添加到ST-GCN层的输出中,相加的结果是最终的输出。
这里的空间残差连接是跨域的。时空融合网络由空间图卷积分支和时空卷积分支组成。恒等映射是图中的下流。与原始的ResNet不同,此处的恒等映射由图卷积组成,该图卷积也可以视为特殊的双流结构,其中一个流学习静态特征,而另一个流学习时空特征。通过2D空间图卷积,可以提取静态空间特征。由于残差连接,残差图将注意静态空间信息。原始层只需要重视时空信息。这种设计使GCN可以更有效地从视频中学习重要信息。
密集连接块Dense Connection Block (DCB)
它的结构非常简单,由几个密集的连接块组成。在每个块中,每个图层的特征图都与相同尺度的所有先前特征连接在一起。通过引入密集连接,将重用每一层的特征。一方面,使用少量的计算,可以获得更丰富的特征图。另一方面,重用特征更强大,因此减少了不同层之间的依赖性。
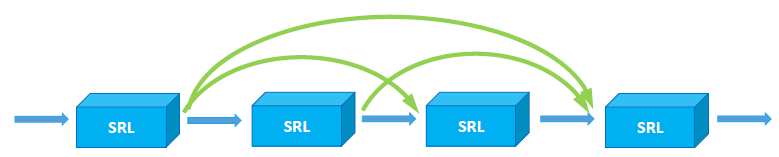
图3.每个密集的连接块都包含几个空间残差层。 在这里,除了第一层或最后一层,每层输入特征的大小与上一层的输出大小完全相同。
在每个密集连接块中,每一层都已连接到所有后续层。 在通道中将它们全部串联在一起。 这样,可以在以后的层中重用先前层所提取的大多数信息。 就像DenseNet一样,此块允许整个网络充分利用全局信息。 最重要的是,从特征的角度来看,通过特征重用和旁路设置,可以大大减少网络参数的数量,并在一定程度上缓解了梯度消失的问题。 另一方面,每一层的输入不仅包括前一层的输出,而且还包括其他先前的层。 这也提高了网络的健壮性。
总体结构
在这里,将空间残差层和密集连接块组合在一起,以形成最终的体系结构,称为SDGCN。注意,几个空间残差层构成一个块。引入密集连接来连接每个块中的这些层。整个网络结构由3个密集连接块组成。在每个块中,通道大小的设置可以充分利用密集连接。采用原始ST-GCN的设置,这确保了所提出的方法可以应用于常用的ST-GCN结构。
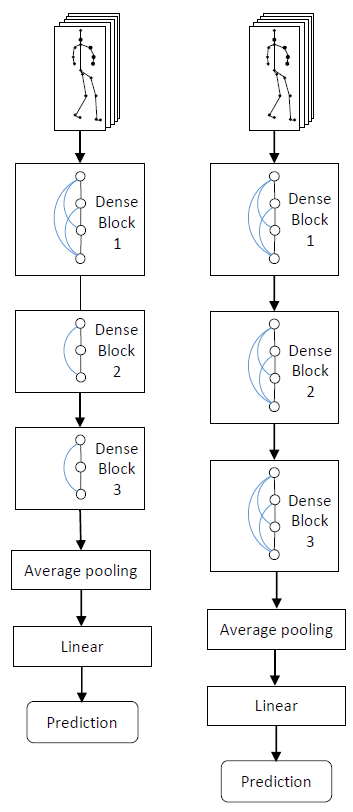
图4.左:基于DCB1的SDGCN。 遵循标准的ST-GCN模型来设计模型。右:基于DCB2的SDGCN。 与左图相比,为了充分探讨密集连接的作用,引入了更多的层和密集连接。空心圆表示SRL。
实验部分
消融实验
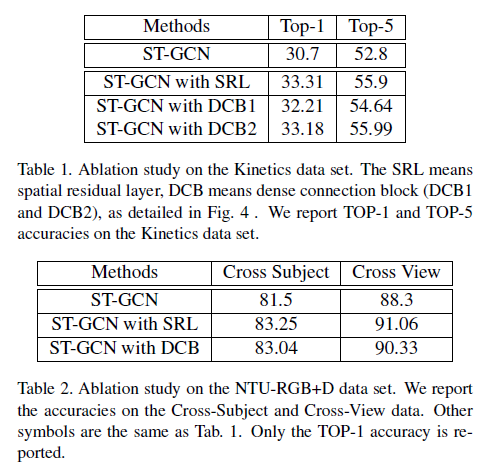
表1.在Kinetics数据集上的消融实验。 SRL表示空间残差层,DCB表示密集连接块(DCB1和DCB2),如图4所示。 报告了在Kinetics数据集上的TOP-1和TOP-5准确率。
表2.在NTU-RGB+D数据集的消融实验。 我们报告交叉对象和交叉视图数据上的准确性。 其他符号与Tab相同。 只上报TOP-1准确率。
对Kinetics和NTU-RGB + D进行详细的实验比较
空间残差层
首先以STGCN 为基准,探索跨域空间残差层的有效性
与原始结构相比,对于由空间图卷积运算和时间卷积串联组成的每个时空结构,我们向原始网络引入空间残差连接,简称为SRL,并保留其他条件不变
发现与基线方法相比,带有SRL的ST-GCN表现出明显的改进
在Kinetics上,性能提高了2.61%
对于NTU-RGB + D,Cross-Subject和Cross-View的性能分别提高了1.75%和2.76%
密集连接块
DCB1基于原始结构,包含10层。为了演示密集连接的作用,设计了DCB2,它包含12层
具有DCB1的ST-GCN的性能提高了1.51%,具有DCB2的ST-GCN的性能提高了2.48%
显然,密集的连接为我们的网络做出了很大的贡献,但是,随着密集连接的增加,网络参数的数量迅速增加。此外,盲目的累积网络复杂性可能导致某些数据集的模型过度拟合。
结果比较
为了进行全面的比较,选择将我们的方法与两个重要的基线相比:ST-GCN 和2s-AGCN 。第一个基准是基于骨骼的动作识别方面的开创性工作,而2s-AGCN是最新的最佳方法。将SRL和DCB合并在一起以报告最终结果。最终模型表示为SDGCN。
与基于ST-GCN的方法相比,在Kinetics上的准确性提高到34.06%,在Cross-Subject和Cross-View测试中分别提高到84.04%和91.43%。
当2s-AGCN作为基准时,在Kinetics上,所提出的方法达到了37.35%的精度。在NTU-RGB + D上,Cross-Subject和Cross-View数据的准确度分别为89.58%和95.74%
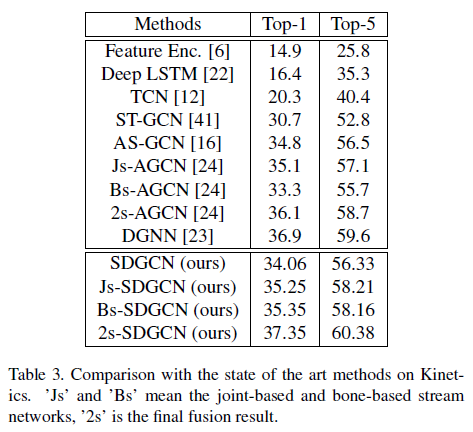
表3 与目前最先进的方法在Kinetics数据集上的比较
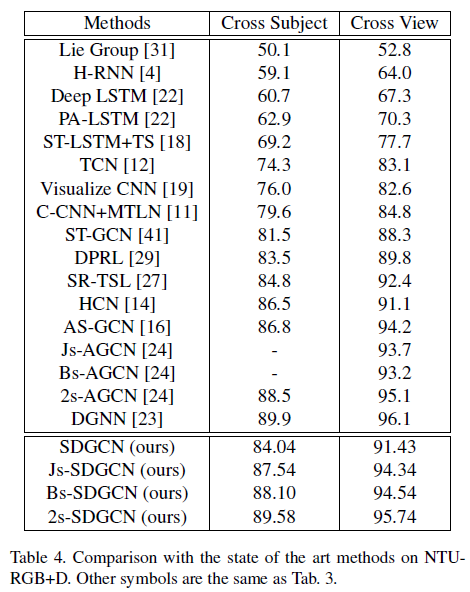
表4.在NTURGB+D上与现有方法的比较
小结
提出了一个统一的时空图卷积网络框架,称为SDGCN,以提高基于骨架的动作识别的性能。通过引入跨域空间图残差层和密集连接块,充分利用了时空信息,提高了时空信息处理的效率。可以很容易地将其合并到主流的时空图网络中。