前提
在这里我们编译的是Spark2.2.0,Hadoop版本为hadoop-2.6.0-cdh5.7.0,Scala版本为2.11.8
更多关于编译Spark2.2.0参见Spark编译官方文档
环境要求
The Maven-based build is the build of reference for Apache Spark. Building Spark using Maven requires Maven 3.3.9 or newer and Java 8+. Note that support for Java 7 was removed as of Spark 2.2.0.
- Java需要7+版本,而且在Spark2.0.0之后Java 7已经被标识成deprecated了,但是不影响使用,但是在Spark2.2.0版本之后Java 7的支持将会被移除;
- Maven需要3.3.9+版本
编译
最后两个包可不用提前下,如不提供,则在编译时,会通过maven源自动下载下来,不挂VPN会很慢,节约时间可预先下好解压放在源码目录下build文件夹下
编译spark要内存够大
在/etc/profile下加入export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
如果不加入这些参数到MAVEN_OPTS,可能会出现下面的错误1
2[INFO] Compiling 203 Scala sources and 9 Java sources to /Users/me/Development/spark/core/target/scala-2.11/classes...
[ERROR] Java heap space -> [Help 1]应为我这里使用的是CDH版的Hadoop所以需要在源码文件夹下的
pom.xml中添加如下,位置在 第一个<repositorys>内,不然编译过程报错找不到对应的jar1
2
3
4<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
编译方法
使用build/mvn 来编译
build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0 -DskipTests clean package
(-Pyarn 提供yarn支持 ,—Phadoop-2.6 提供hadoop支持,并且指定hadoop的版本)
用build目录下自带的mvn来部署安装,它可以自动提供部署工程所需要的资源,并把资源下载到build目录下,如果用户提供合适的参数来部署的话,就选择用户的,如果没有提供,那么mvn也可以给他配置默认的参数和资源
编译完成后,你会发现在assembly/build下面多了一个target文件,这个就是编译的结果
用make-distributed 脚本来编译
编译完源代码后,虽然直接用编译后的目录再加以配置就可以运行spark,但是这时目录很庞大,部署起来很不方便,所以需要生成部署包。生成在部署包位于根目录下,文件名类似于spark-[spark版本号]-bin-[Hadoop版本号].tgz
使用命令如下1
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Phive -Phive-thriftserver -Dhadoop.version=2.6.0-cdh5.7.0
在这里解释下该命令:1
2
3
4
5
6
7--name:指定编译完成后Spark安装包的名字
--tgz:以tgz的方式进行压缩
-Psparkr:编译出来的Spark支持R语言
-Phadoop-2.6:以hadoop-2.6的profile进行编译,具体的profile可以看出源码根目录中的pom.xml中查看
-Phive和-Phive-thriftserver:编译出来的Spark支持对Hive的操作
-Pmesos:编译出来的Spark支持运行在Mesos上
-Pyarn:编译出来的Spark支持运行在YARN上
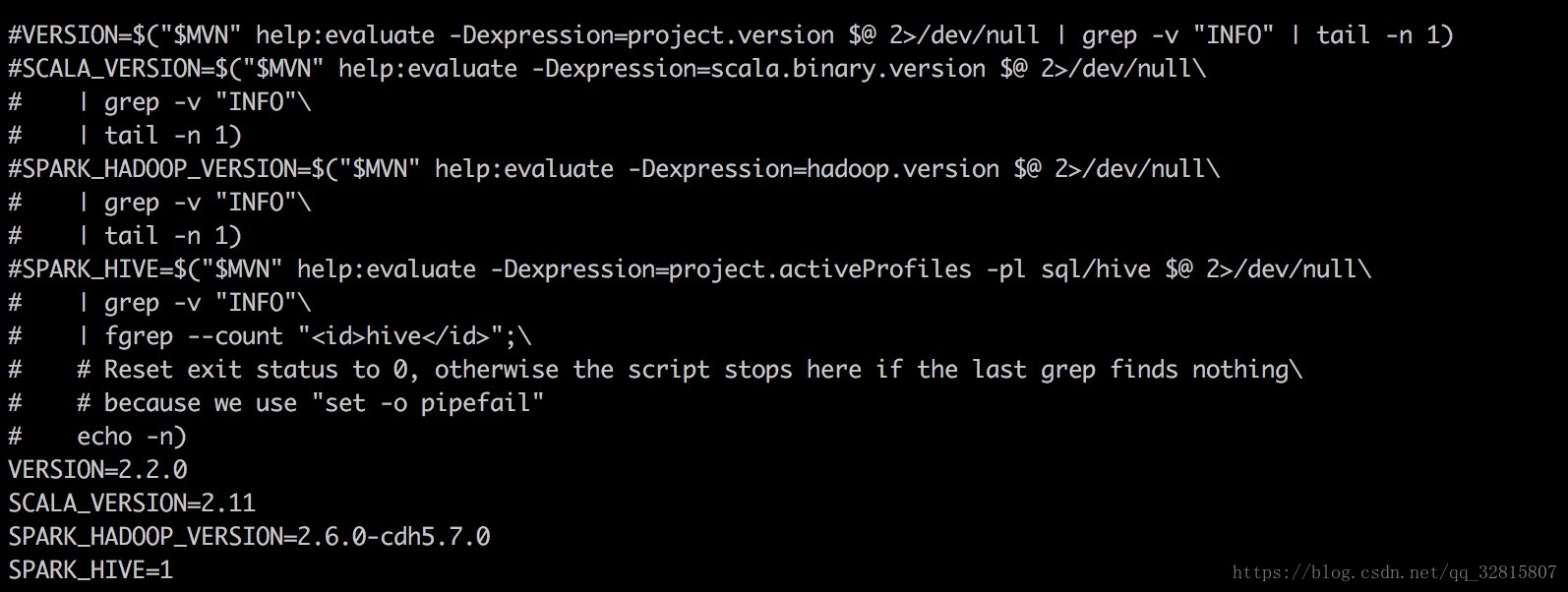
也可修改dev目录下make-distribution.sh脚本这样速度更快
将VERSION,SCALA_VERSION ,SPARK_HADOOP_VERSION ,SPARK_HIVE 注释掉,直接写上自己的版本1
2
3
4VERSION=2.2.0 #Spark版本
SCALA_VERSION=2.11 #Scala版本(大版本)
SPARK_HADOOP_VERSION=2.6.0-cdh5.7.0 #Hadoop版本
SPARK_HIVE=1 #是否将Hive打包(非1表示不打包)
也可以将默认使用的build目录下自带的mvn修改为自己maven,使用速度快的mirror,这样编译能更快更稳定

编成功后生成的部署包位于根目录下,文件名类似于spark-$spark-version-bin-$Hadoop-version.tgz 即可解压使用了!